看到华人小哥,必须得关注一下,演讲题目是《Implement Standard Library: Design Decisions, Optimisations and Testing in Implementing Libc++》,作者Hui Xie是libc++的贡献者、BSI成员、WG21成员……谈了一些libc++中相关的设计决策、优化和测试细节。本文结合演讲视频和仓库幻灯片整理而来,任何转述错误和个人观点与原作者无关,推荐观看原视频,原作者的讲解更清晰。
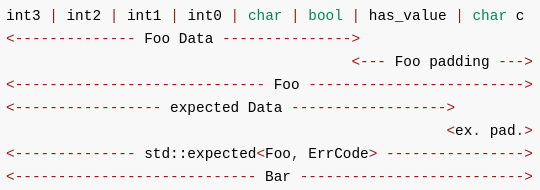
因为 「The attribute-token no_unique_address specifies that a non-static data member is a potentially-overlapping subobject」,class Foo不是C结构体,其尾部padding被复用了。收益是更小的内存占用,更好的缓存局部性,std::expected通常用于错误处理,并用于返回值,对于如下代码:
断言失败了!因为 「To zero-initialize an object or reference of type T means: … if T is a (possibly cv-qualified) non-union class type, its padding bits ([basic.types.general]) are initialized to zero bits and …」 ,邻居表示,我清扫自家院子,把空地的杂物扔了,也怪不得我啊!对于class Foo,construct_at会将padding字段清零,附带着has_val_也被清零了,修复该问题的办法就是将has_val_的赋值挪到调用std::construct_at之后,修改如下:
template<classVal,classErr>classexpected{structrepr{unionU{[[no_unique_address]]Valval_;[[no_unique_address]]Errerr_;};[[no_unique_address]]Uu_;boolhas_val_;};reprrepr_;// no [[no_unique_address]] on this member
};
template<classVal,classErr>structrepr{unionU{[[no_unique_address]]Valval_;[[no_unique_address]]Errerr_;};[[no_unique_address]]Uu_;boolhas_val_;};template<classVal,classErr>structexpected_base{repr<Val,Err>repr_;// no [[no_unique_address]]
};template<classVal,classErr>requiresbool_is_not_in_paddingstructexpected_base{[[no_unique_address]]repr<Val,Err>repr_;};template<classVal,classErr>classexpected:expected_base<Val,Err>{};
classFoofinal{inti;charc;boolb;public:voidclear()noexcept{// *this = {}; // Good, but little bit slow.
std::memset(this,0,sizeof(*this));// Bad, but fast.
}};enumclassErrCode:int{Err1,Err2,Err3};static_assert(std::is_trivially_copyable_v<Foo>);intmain(){std::expected<Foo,ErrCode>e{Foo{}};static_assert(sizeof(e)==8);e.value().clear();assert(e.has_value());return0;}// clang++ -std=c++23 -stdlib=libc++
class__stop_state{std::atomic<bool>stop_requested_;std::atomic<unsigned>stop_source_count_;// for stop_possible()
std::list<stop_callback*>stop_callbacks_;std::mutexlist_mutex_;};static_assert(sizeof(__stop_state)==72);static_assert(sizeof(stop_token)==16);
libc++优化实现大体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class__stop_state{// The "callback list locked" bit implements a 1-bit lock to guard
// operations on the callback list
//
// 31 - 2 | 1 | 0 |
// stop_source counter | callback list locked | stop_requested |
atomic<uint32_t>state_=0;// Reference count for stop_token + stop_callback + stop_source
atomic<uint32_t>ref_count_=0;// Lightweight intrusive non-owning list of callbacks
// Only stores a pointer to the root node
__intrusive_list_view<stop_callback_base>callback_list_;};static_assert(sizeof(__stop_state)==16);static_assert(sizeof(stop_token)==8);